
Google processes an estimated 16.4 billion search queries every day. This equates to approximately 189,815 searches per second. And Google is able to answer them with the help of its actively managed index. The Google Search index covers hundreds of billions of webpages and is well over 100,000,000 gigabytes in size.
Understanding how Google Search works is a fundamental skill for anyone with a website or online presence. Whether you’re a budding blogger, a small business owner, or simply curious about the magic behind search results, this comprehensive guide will demystify the processes Google uses to find, analyze, and prioritize the vast information on the web. I’ll demystify Google’s crawling and indexing processes, decode common errors like “Crawled – currently not indexed,” and reveal how to leverage Google’s own patent strategies to boost your rankings. Let’s dive in.
1. Demystifying How Google Search Works
At its core, a search engine is an intricate system designed to help users find information on the internet. Think of it as a massive digital librarian, constantly organizing and cataloging the ever-expanding world of online content. For a search engine like Google to function effectively, it employs a sophisticated three-step process: Crawling, Indexing, and Serving (Ranking).
The first step, Crawling, is akin to the librarian exploring the shelves, discovering new books and noting their existence. Google uses automated software programs called web crawlers, often referred to as spiders or bots (like Googlebot), to navigate the internet. These crawlers follow links from one webpage to another, systematically discovering new and updated content.
Once content is discovered, the next stage is Indexing. This is where the librarian reads and catalogs the books, making them searchable in the library’s index. Google analyzes the text, images, videos, and other media on a crawled page to understand its content and meaning. This information is then stored in Google’s vast search index, a massive database of all the content Google has found and deemed worthy of inclusion.
Finally, when you perform a search, the Serving (Ranking) stage comes into play. This is when the librarian retrieves the most relevant books from the index and presents them in an order that is most helpful to your query. Google’s algorithms search its index to find pages that match your search terms and then rank these results based on numerous factors, including relevance, quality, and usability.
It’s crucial to understand that this three-step process is not a one-time event but a continuous cycle. Google is constantly crawling and re-indexing the web to ensure its index remains fresh and up-to-date, reflecting the ever-changing landscape of online information. This continuous nature underscores the importance of ongoing SEO efforts to maintain and improve your website’s visibility.
2. Google’s Crawling Explained
Crawling is the foundational process through which Googlebot, Google’s primary web crawler, discovers and analyzes the immense amount of information available on the internet. Think of Googlebot as a tireless explorer, systematically navigating the web to find new and updated webpages. This process is essential for Google to build and maintain its comprehensive search index.
The frequency with which Googlebot crawls a website is not uniform; it varies depending on several factors, including the site’s popularity, how often it’s updated, and what’s known as its crawl budget.
Generally, websites with higher authority and those that publish new content regularly tend to be crawled more often.
For instance, a well-established news website that posts multiple articles daily will likely be crawled far more frequently than a small personal blog that is updated sporadically.
Factors such as the website’s domain authority, the number and quality of backlinks it has, and even the age of the site influence how often Googlebot visits. The crawling speed is unique to every single site and based on below factors:

Googlebot identifies URLs to crawl through several key pathways. It often starts with a set of initial URLs and then follows the links it finds on those pages to discover new content. This link-following behavior allows Googlebot to traverse the interconnected web.
Another crucial way Googlebot finds URLs is through sitemap submissions. Website owners can create and submit XML sitemaps via Google Search Console, providing Google with a direct roadmap of all the important pages on their site.
This is particularly beneficial for new websites or large sites with complex structures, ensuring that all pages are discoverable. Furthermore, Googlebot continuously discovers new pages as it crawls, by extracting links from the pages it visits.
Central to Google’s crawling process, especially for managing efficiency on a massive scale, is the concept of the “importance threshold,” as outlined in Google’s patent US7509315B1. This threshold is a dynamic value that helps Googlebot prioritize which URLs to crawl.

Once Google’s systems have crawled and indexed a significant number of pages, particularly up to a certain limit, they use this importance threshold to decide whether to crawl additional, newly discovered URLs.
URLs deemed more important, based on various ranking signals, are more likely to be crawled, ensuring that Googlebot focuses its resources on the most valuable and relevant content.
This mechanism is particularly vital for managing the crawl budget effectively, preventing Googlebot from spending too much time on less important or low-quality pages.
3. Understanding Google’s Indexing Process
Once Googlebot has diligently crawled webpages across the internet, the next critical step is indexing.
Indexing is the process where Google analyzes the content gathered during the crawl and stores it in its vast search index. This index is essentially a massive, constantly updated database of all the webpages Google knows about, making it possible to quickly retrieve relevant information in response to search queries.
Google employs specific criteria to determine which crawled pages will be indexed.
Content quality and relevance are paramount; Google aims to index pages that offer valuable and informative content to users. The authority and trustworthiness of the website also play a significant role. Websites considered reputable and authoritative are more likely to have their pages indexed.
Technical factors, such as the website’s structure, page loading speed, and mobile-friendliness, are also taken into account. Additionally, Google respects directives like ‘noindex’ tags, which explicitly tell search engines not to include a page in their index.
It’s a common misconception that every page Google crawls will automatically be indexed. In reality, Google is selective about what it adds to its index.
Several reasons can lead to a crawled page not being indexed.
- One common reason is low-quality or thin content. Pages that lack substantial information or offer little value to users are less likely to be indexed.
- Duplicate content is another major factor. If a page’s content is very similar to other pages on the same site or across the web, Google may choose to index only one version.
- As mentioned earlier, pages containing ‘noindex’ meta tags will also not be indexed, as this is a direct instruction from the website owner.
- Technical issues encountered during crawling or rendering can sometimes prevent a page from being indexed successfully.
Google’s ultimate goal is to provide users with the highest quality and most relevant search results, so its indexing process is designed to filter out content that doesn’t meet these standards.
4. Analyzing Which Pages Google Can Find and Index
Google Search Console is an invaluable tool that provides website owners with crucial insights into how Google sees their website, including which pages Google can find and index. The “Page Indexing Report” within Search Console offers a comprehensive overview of your website’s indexing status.
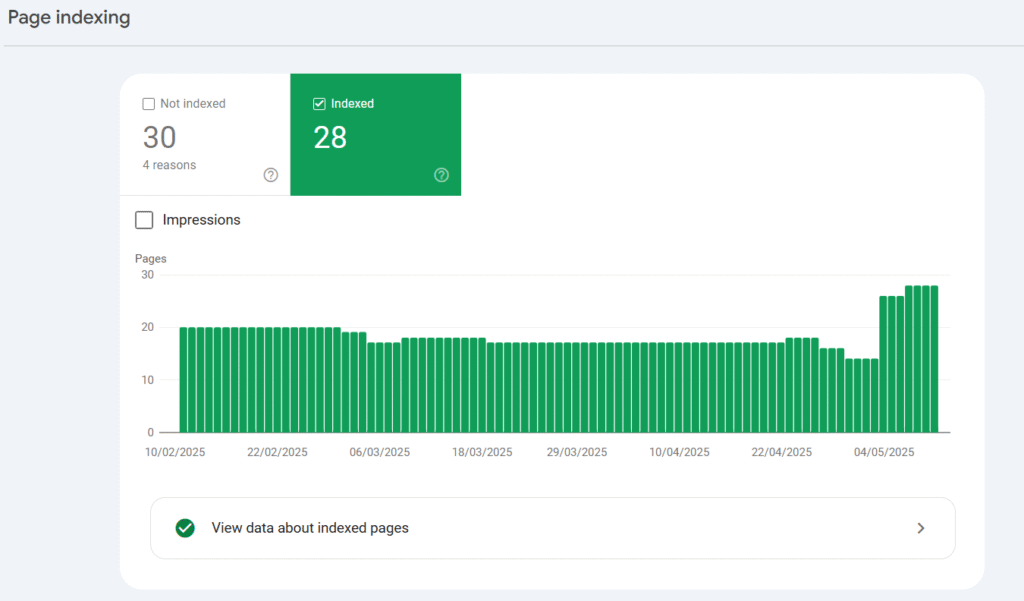
Interpreting your indexing status report involves looking at the overall number of pages that have been indexed compared to those that haven’t. Ideally, you should see a gradual increase in the count of indexed pages as your website grows.
Drops or unexpected spikes in these numbers warrant further investigation. The report highlights critical areas such as the breakdown of indexed versus non-indexed pages and information about canonical pages.
- Indexed Pages are URLs that Google has successfully processed and added to its search index.
- Not Indexed Pages are URLs that Google attempted to index but couldn’t or chose not to, and the report provides reasons for this.
- Canonical Pages are the preferred versions of pages when there are multiple URLs with similar content; Google typically indexes only the canonical version.
The Page Indexing Report also provides actionable steps for troubleshooting indexing issues. For non-indexed URLs that are intentionally blocked by robots.txt, you can use the robots.txt Tester within Search Console to identify the blocking rules and modify your robots.txt file accordingly.

If pages are excluded due to noindex tags, you’ll need to check the HTML source of those pages and remove the tag if you want them to be indexed. The report also helps in identifying server errors, often indicated by 5xx status codes. You should monitor these errors and investigate your server’s health.
Soft 404s, which are pages that appear to users as error pages but return a 200 OK status code to search engines, can also be identified. These should be corrected by either returning a proper 404 status code or by adding meaningful content to the page.

The report can highlight issues with redirect loops, where a URL redirects to another, which then redirects back to the original URL, creating an endless loop. These redirect chains need to be examined and fixed to ensure a clear path to the intended content.
Regularly reviewing and acting upon the information in the Page Indexing Report is crucial for ensuring that Google can effectively find and index your website’s important content, ultimately impacting its visibility in search results.
5. Diving Deep into Indexing Statuses: “Crawled – Currently Not Indexed” vs. “Discovered – Currently Not Indexed”
Within the Google Search Console’s Page Indexing Report, two statuses often cause confusion: “Crawled – currently not indexed” and “Discovered – currently not indexed”. Understanding the distinction between these statuses is crucial for effectively troubleshooting indexing issues.
The status “Crawled – currently not indexed” signifies that Googlebot has visited and analyzed the content of the page, but for some reason, has decided not to include it in the Google Search index yet.
This means Google is aware of the page’s content but has chosen not to index it at this time. Several potential reasons can lead to this status.
- One common cause is low content quality or thin content. If Google deems the content on the page to be lacking in substance, originality, or value to users, it might choose not to index it.
- Duplicate content is another frequent reason. If the page’s content is very similar to other pages already indexed on your site or elsewhere, Google may filter it out.
- Poor internal linking can also contribute to this status. If a page doesn’t have enough internal links pointing to it, Google might perceive it as less important.
- In the case of e-commerce websites, out-of-stock or expired product pages might also receive this status.
- Additionally, there can sometimes be indexing delays where Google has crawled the page but hasn’t fully processed it into the index.
On the other hand, the status “Discovered – currently not indexed” indicates that Google has found the URL of the page, but has not yet crawled it. This typically means that Google intended to crawl the URL but anticipated that doing so might overload the website, so the crawl was rescheduled.
Several common scenarios can lead to this status.
- For large websites with many pages, crawl budget constraints can be a factor. Google allocates a certain amount of resources to crawl each website, and if the number of URLs exceeds this budget, some pages might be discovered but not crawled immediately.
- Server overload or general website performance issues can also cause Google to postpone crawling. If your server is slow to respond or frequently experiences downtime, Googlebot might delay crawling new URLs to avoid further straining your resources.
- In some instances, Google might assume a low page quality based on other signals from your website and thus deprioritize crawling certain URLs.
- Poor internal linking can also lead to this status if Google struggles to find a clear path to the discovered URL.
To address the “Crawled – currently not indexed” status and improve indexing chances, it’s advisable to:
- Focus on enhancing the quality and uniqueness of the page’s content.
- Review and address any potential duplicate content issues by implementing canonical tags or redirects.
- Strengthen the internal linking to the affected page from other relevant pages on your site.
After making these improvements, you can use the URL Inspection tool in Google Search Console to request indexing, prompting Google to re-evaluate the page.
For the “Discovered – currently not indexed” status, a primary step is to also request indexing of the URL through Google Search Console. Additionally, it’s important to investigate and improve your website’s performance and server response time.
If you have a large website, consider strategies for optimizing your crawl budget, such as preventing Googlebot from accessing low-value URLs. Ensure that the discovered page has sufficient internal links pointing to it , and double-check that the page is not unintentionally blocked by your robots.txt file.
It is important to understand the nuances of these two indexing statuses and take targeted actions. Doing this you can significantly increase the likelihood of your important pages being included in Google’s search index.
6. How Google Manages its Search Index
Maintaining an efficient and comprehensive search index is a monumental task, and Google employs sophisticated methodologies to achieve this.
A cornerstone of this process is continuous crawling.
Google’s web crawlers, like Googlebot, are constantly exploring the internet, discovering new webpages and revisiting existing ones to identify updates. This ongoing process ensures that Google’s index remains as current as possible, reflecting the dynamic nature of the web.
When these crawlers discover a webpage, Google’s systems proceed to sort and organize the content. This involves rendering the page, much like a web browser would, and analyzing various key signals, from the keywords used to the freshness of the website.
All this information is meticulously tracked and stored within the Search index. It’s important to note that Google’s indexing efforts extend beyond just traditional webpages.
The Search index encompasses a vast array of information types, including images, videos, books, and data from diverse sources, all gathered through crawling, partnerships, and Google’s own knowledge repositories like the Knowledge Graph.
Google utilizes continuous indexing, a process where the index is updated on an ongoing basis rather than through large, infrequent batches.
This allows for more timely inclusion of new content and updates to existing content in the search results. While these continuous updates happen frequently, Google also rolls out periodic index updates, including core updates, which can have a more significant impact on how content is assessed and ranked.
The prioritization of content for indexing is guided by numerous factors, including the relevance of the content to potential search queries, the quality and authority of the source, the usability of the webpage, and the overall context of the information.
Furthermore, Google’s management of its search index is closely tied to URL management based on importance rank, as detailed in its patent guidelines. Given the sheer volume of information on the web and the practical limitations of indexing everything, Google employs importance rank to prioritize which URLs are most critical to crawl and include in the index.
Pages deemed less important, based on various metrics, may be skipped during crawling or even removed from the index to make way for content considered more valuable to users. This approach ensures that Google’s search index remains efficient and primarily contains the most relevant and high-quality information available.
7. Importance Threshold and Crawl Priority: How Google Decides
The concept of the “Importance Threshold” is a critical element in how Google manages its vast crawling operations. This threshold acts as a dynamic benchmark that Google uses to decide whether to crawl additional URLs after its systems have already indexed a significant number of pages, often up to a predefined target.
Google employs a sophisticated ranking system to determine the crawling priority of URLs, differentiating between those deemed high importance and low importance.
Several factors contribute to a URL’s importance rank.
- One key factor is its popularity, which Google assesses through metrics such as the page’s view rate and its PageRank – a measure of the page’s authority based on the number and quality of backlinks it receives.
- The overall quality of the website hosting the URL also plays a significant role, as does the speed and responsiveness of the server.
- URLs associated with websites that are considered authoritative and provide high-quality content are more likely to exceed the importance threshold and receive higher crawl priority.
The Google patent (US7509315B1) provides examples of how importance rank might be considered. Pages with a high PageRank, indicating strong authority, would likely have a high importance rank.
Similarly, pages that receive a high volume of views from users would also be considered important.
Conversely, newer pages or those with fewer links pointing to them might initially have a lower importance rank. However, this rank can be dynamic, changing over time as a page gains more authority or popularity.
For webmasters and SEO strategists, understanding the implications of the importance threshold is vital. Since Googlebot might not crawl every URL it discovers, particularly on large websites, it’s crucial to ensure that your important pages exceed this threshold to be crawled and ultimately indexed.
To achieve this, a primary focus should be on creating high-quality, unique, and valuable content that attracts user engagement and earns backlinks from reputable sources. Improving your website’s speed and overall user experience also contributes to a higher perceived importance by Google.
Several SEO strategies can enhance crawl frequency and indexing, increasing the likelihood that your pages meet Google’s importance criteria.
- Regularly updating your website content signals to Google that your site is active and provides fresh information, which can lead to more frequent crawling.
- Maintaining an organized site structure with clear navigation helps Googlebot efficiently find and understand all your important pages.
- One crucial recommendation is to improve your internal linking structure. This involves creating a clear and logical hierarchy within your website and strategically linking related content together. Well-placed internal links help Googlebot navigate your site efficiently, discover all your important pages, and understand the relationships between different pieces of content. Use descriptive anchor text for your internal links to provide context about the linked page.
- Another vital step is to optimize your sitemap submissions and updates. Create an XML sitemap that lists all the important URLs on your website and submit it to Google Search Console. Ensure your sitemap is accurate and up-to-date, reflecting any changes or additions to your site’s content. You can also add the location of your sitemap to your
robots.txtfile to make it easily accessible to search engine crawlers. - Regularly review and validate issues using Google Search Console is also paramount. The Page Indexing Report in Search Console provides valuable insights into your site’s indexing status, highlighting any errors or warnings. Pay close attention to the reasons why pages aren’t being indexed and take steps to address these issues. After you’ve implemented fixes for indexing problems, utilize the “Validate fix” option within the report. This process prompts Google to recrawl and re-evaluate the affected URLs. You can then monitor the validation status to confirm whether your fixes have been successfully recognized by Google. By consistently monitoring and validating your site’s indexing status, you can ensure that your content is discoverable and performing well in Google Search.
8. Common FAQs and Myths About Google’s Indexing
Why isn’t my page indexed immediately after publishing?
The reality is that crawling and indexing take time and depend on various factors. For new websites, it can take anywhere from a few hours to several weeks for Google to index content. You can expedite this process by submitting your sitemap in Google Search Console and using the URL Inspection tool to request indexing for individual pages.
How to remove pages from Google’s index?
The most effective way to remove pages is through the Removals Tool in Google Search Console. This tool allows you to temporarily hide pages from search results and request their permanent removal from Google’s index.
Why is Google indexing pages I blocked via robots.txt?
It’s important to understand that the robots.txt file primarily prevents Googlebot from crawling specific pages, not necessarily from indexing them if Google finds the URL through other sources, such as links from other websites. To truly prevent a page from being indexed, you should use a noindex meta tag.
Several myths also surround Google’s indexing process. One common misconception is that Google has a specific word count guideline for indexing content.
In fact, Google focuses on the quality and relevance of the content, not a specific number of words.
Another myth is that Google automatically indexes every page on the internet quickly. Indexing is a selective process, and the time it takes can vary significantly depending on factors like website authority and content quality.
Also, some believe that Domain Authority (a metric by Moz) is a direct Google ranking factor. While Domain Authority can be a useful indicator of a website’s overall SEO health, it is not a metric directly used by Google in its ranking algorithms.
9. Future Outlook: Staying Ahead in SEO
The landscape of Google’s indexing practices is constantly evolving, and staying ahead requires webmasters and SEO professionals to be aware of emerging trends and anticipated changes.
One significant trend is the continued emphasis on mobile-first indexing, where Google primarily uses the mobile version of a website to crawl and index content. Ensuring your website provides a seamless and comprehensive experience on mobile devices is crucial for future indexing success.
The increasing role of Artificial Intelligence (AI) and machine learning in Google’s algorithms will also impact indexing. AI is being used to better understand content quality, relevance, and user intent, which will likely influence how Google selects and prioritizes pages for indexing. There’s also the potential for real-time indexing to become more prevalent for certain types of content, allowing for near-instantaneous inclusion of timely information in search results.
Google’s continued focus on E-E-A-T (Experience, Expertise, Authoritativeness, and Trustworthiness) will likely play an even greater role in index selection. Websites that demonstrate strong E-E-A-T signals will be favored, emphasizing the importance of creating credible and trustworthy content. Some experts also anticipate a potential shift towards more selective indexing by Google, where only the most valuable and unique content is prioritized for inclusion in the index.
To navigate these future changes and stay ahead in SEO, it’s essential to remain updated on Google’s algorithm updates and best practices. Regularly auditing and optimizing your website’s technical SEO will continue to be crucial. Above all, the focus should remain on creating high-quality, user-centric content that provides genuine value to your audience. By staying informed and proactive, you can ensure your website remains discoverable and competitive in the ever-evolving world of Google Search.
Conclusion
Understanding how Google crawls, indexes, and prioritizes web pages is no longer an optional extra but a fundamental requirement for online success. By grasping the intricacies of these processes, from the initial discovery of content by Googlebot to the final selection of pages for the search index based on the importance threshold, SEO beginners and seasoned professionals alike can make informed decisions to enhance their website’s visibility.
The insights gained from analyzing the Page Indexing Report in Google Search Console, coupled with a clear understanding of the different indexing statuses, provide actionable steps for troubleshooting and improvement. As Google continues to refine its algorithms and adapt to the evolving web, staying updated on these core mechanisms and future trends will be paramount for maintaining a strong online presence.












